Introduction
WDSPdb 2.0
- WDSP database (created in 2014) is a free and comprehensive resource to provide high quality structural information of WD40 proteins as well as the featured sites. WDSPdb 2.0 has recorded about 600,000 predicted WD40 proteins from 4,426 species.
- It provided accurate structure predictions and featured sites annotations specifically for WD40 domains, based on the WDSP tool.
- It provided the general information of each WD40 protein and their cross-references linked to other well-known databases.
- It exhibited the 3D structure models for WD40 proteins whose repeat counts are 6, 7 or 8 modeled by MODELLER software.
- It mapped about 40,000 substitutions to 252 WD40 proteins from Swiss-Prot section with relatively higher confidence categories (“High”). Besides the general information of variants, we not only provided the special annotations include exact secondary structures locations, featured site identifications (hydrogen bond network, potential hotspots on the top face), but also presented the information obtained from other databases, like pathogenic predictions in dbNSFP,cancer driver mutation from the IntOgen, cancer highly recurrent mutations from the cBioportal and mutations have been experimentally shown to affect the PPIs from the IntAct.
- It deployed the updated WDSP tool with options of parameter tuning (the searching database and the iterative times), which would provide better predictions for user' own sequences.
WD40 Repeat Protein
- The WD40-repeat domains are one of the most popular interactors in protein-protein interaction (PPI) networks. By acting as scaffolds, they assemble various molecular machineries, and play versatile roles in fundamental biological processes including signal transduction, ubiquitination, cell cycle control, etc.
- WD40 domain is a β-propeller usually formed by 6-8 repeats, and the sequence of one single repeat contains 40-60 residues with conserved GH and WD dipeptides.
- Each WD40 repeat folds into a four-stranded antiparallel β-sheet (strand d, a, b and c, connected by loops), and is often stabilized by a strong side-chain hydrogen bond network which is widely and uniquely presented in WD40 proteins.
- WD40 domain has three faces, i.e. top, side and bottom faces, to mediate the interactions with partners. The top face is better studied than others, and the potential hotspot residues on this face are exposed into the solvent by the β bulge between the strand a and strand b to participate in interactions.
WDSP
- WD40 repeat protein Structure Predictor (WDSP) is developed to accurately predict the secondary structures of WD40 domains, hydrogen bond networks, and interaction hotspots.
- The WDSP tool adopts a WD40-specific position weight matrix (PWM) and PSIPRED as backends. The experimental structures used for generating the PWM have expanded from 33 to 65 and we replaced PSIPRED from V3 to V4.
- WDSP is the only one tool which can both identify the exact boundaries of WD40 repeat and their structural and functional features up to date.
Statistics
The WDSPdb 2.0 is based on UniProtKB V201707, and the data coverage is about 10 times of WDSPdb1.0.
The statistic of all WD40 proteins in different categories
| Category | WD40 Proteins | WD40 Repeats | Hydrogen Bond Network | Potential Hotspots on the Top Face | Species |
|---|---|---|---|---|---|
| Total | 594,319 | 4,033,034 | 852,295 | 4,963,216 | 4,426 |
| High | 194,182 | 1,575,604 | 709,212 | 2,093,562 | 1,984 |
| Middle | 63,401 | 411,377 | 96,753 | 490,226 | 2,086 |
| Low | 336,736 | 2,046,053 | 46,330 | 2,379,428 | 4,021 |
| Eukaryota | 349,985 | 2,526,886 | 759,192 | 3,165,106 | 1,711 |
| Bacteria | 232,439 | 1,433,214 | 90,131 | 1,711,023 | 2,472 |
| Archaea | 7,272 | 48,997 | 1,779 | 57,419 | 175 |
| Viruses | 680 | 4,043 | 176 | 5,584 | 67 |
| Homo sapiens | 1,941 | 10,698 | 3,388 | 13,087 | |
| Mus musculus | 1,398 | 8,955 | 2,674 | 10,943 | |
| Danio rerio | 950 | 6,900 | 2,025 | 8,519 | |
| Oryza sativa | 791 | 5,290 | 1,544 | 6,565 | |
| Arabidopsis thaliana | 1,232 | 8,718 | 2,397 | 10,813 | |
| Drosophila melanogaster | 688 | 4,682 | 1,282 | 5,718 | |
| Saccharomyces cerevisiae | 176 | 1,197 | 305 | 1,542 | Schizosaccharomyces pombe | 176 | 1,319 | 377 | 1,685 |
Swiss-Prot
The statistic of Swiss-Prot section WD40 proteins in different categories
| Category | WD40 Proteins | WD40 Repeats | Hydrogen Bond Network | Potential Hotspots on the Top Face | Species |
|---|---|---|---|---|---|
| Total | 5,601 | 33,410 | 8,950 | 43,146 | 1,040 |
| High | 2,173 | 16,788 | 8,250 | 23,647 | 191 |
| Middle | 333 | 2,716 | 439 | 3,035 | 110 |
| Low | 3,095 | 13,906 | 261 | 16,464 | 962 |
| Eukaryota | 4,002 | 27,449 | 8,746 | 35,753 | 286 |
| Bacteria | 1,461 | 5,441 | 191 | 6,698 | 679 |
| Archaea | 46 | 151 | 1 | 202 | 26 |
| Viruses | 92 | 369 | 12 | 493 | 49 |
| Homo sapiens | 473 | 3,413 | 990 | 4,205 | |
| Mus musculus | 436 | 3,160 | 899 | 3,845 | |
| Danio rerio | 99 | 673 | 216 | 893 | |
| Oryza sativa | 40 | 335 | 99 | 461 | |
| Arabidopsis thaliana | 307 | 1,960 | 463 | 2,548 | |
| Drosophila melanogaster | 101 | 699 | 178 | 912 | |
| Saccharomyces cerevisiae | 176 | 1,197 | 305 | 1,542 | Schizosaccharomyces pombe | 176 | 1,319 | 377 | 1,685 |
TrEMBL
The statistic of TrEMBL section WD40 proteins in different categories
| Category | WD40 Proteins | WD40 Repeats | Hydrogen Bond Network | Potential Hotspots on the Top Face | Species |
|---|---|---|---|---|---|
| Total | 588,718 | 3,999,624 | 843,345 | 4,920,070 | 4,205 |
| High | 192,009 | 1,558,816 | 700,962 | 2,069,915 | 1,961 |
| Middle | 63,068 | 408,661 | 96,314 | 487,191 | 2,049 |
| Low | 333,641 | 2,032,147 | 46,069 | 2,362,964 | 3,801 |
| Eukaryota | 345,983 | 2,499,437 | 750,446 | 3,129,353 | 1,648 |
| Bacteria | 230,978 | 1,427,773 | 89,940 | 1,704,325 | 2,364 |
| Archaea | 7,226 | 48,846 | 1,778 | 57,217 | 173 |
| Viruses | 588 | 3,674 | 164 | 5,091 | 19 |
| Homo sapiens | 1,468 | 7,285 | 2,398 | 8,882 | |
| Mus musculus | 962 | 5,795 | 1,775 | 7,098 | |
| Danio rerio | 851 | 6,227 | 1,809 | 7,626 | |
| Oryza sativa | 751 | 4,955 | 1,445 | 6,104 | |
| Arabidopsis thaliana | 925 | 6,758 | 1,934 | 8,265 | |
| Drosophila melanogaster | 587 | 3,983 | 1,104 | 4,806 | |
| Saccharomyces cerevisiae | 0 | 0 | 0 | 0 | Schizosaccharomyces pombe | 0 | 0 | 0 | 0 |
Tutorial
Manual
Home Page

- You can hit the “Home” button at the banner to quickly jump to the home page.
- You can hit the “Predictor” button at the banner and jump to the WDSP predictor page to conduct the WD40 repeat prediction of your own sequences.
- You can use the “Help” page to learn how to use the database or predictor and understand the provided information. If you have any questions, please feel free to contact with us by “Contact” page.
- You can push the "Categories" button on the banner to access the WD40 proteins belong to the different UniProt sections, different confidence categories, taxonomy or model organisms.
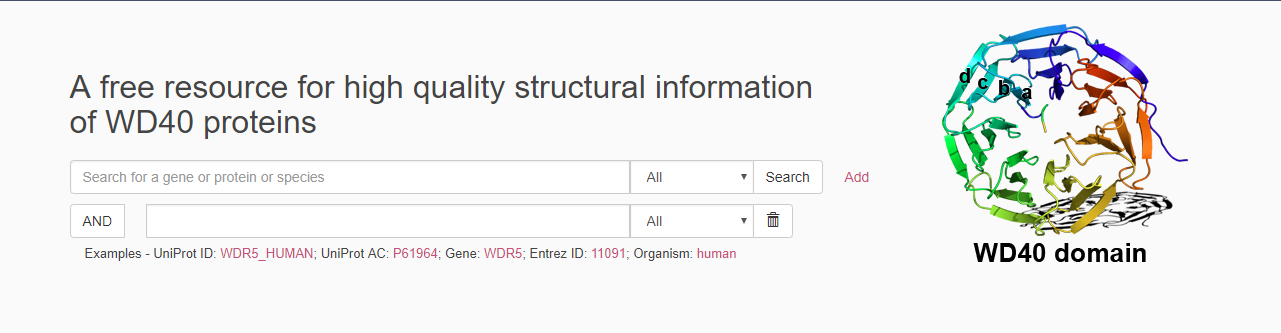
- You can get started by using the search bar in the prominent of the home page to search the proteins using different classification identifier. There is a drop-down list that allows selecting the classification. You can input the gene name, UniProt accession number, UniProt entry name, entrez gene ID or organism to search.
- You can also add multiple search bars via the "Add" button on the right. Then you can search proteins by using multiple conditions.

- You can quickly learn about the WDSPdb 2.0 and the introductions of WD40 repeat proteins, WDSP tool, structural feature: hydrogen bond network, functional feature: hotspots on the top face.
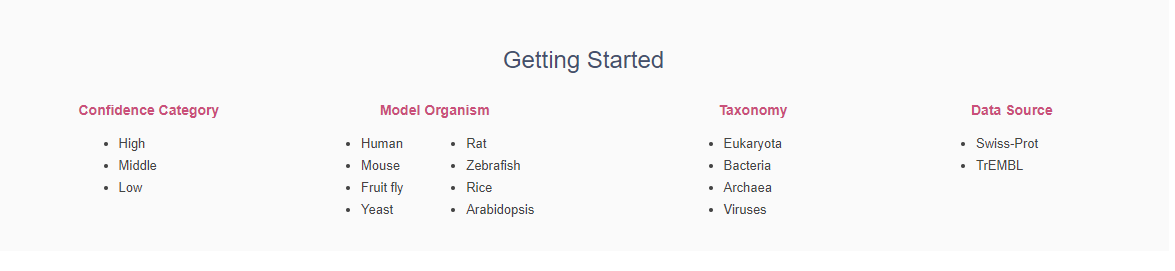
- Additionally, you can get started from different classifications or pages listed below the brief introductions.

- If you use the data of WDSPdb or the WDSP in you research, please cite the associated papers.
Search Result Page
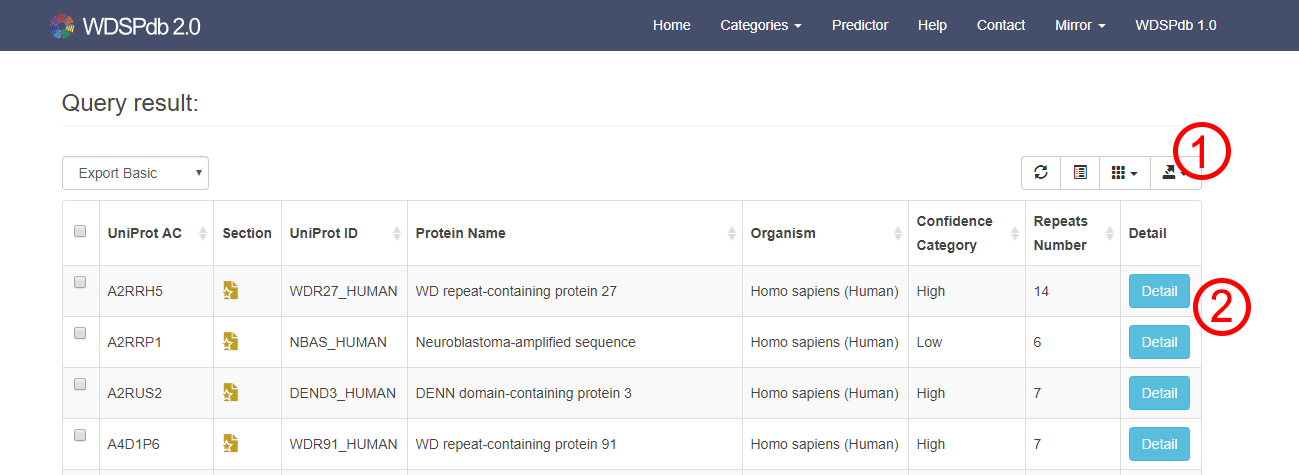
- The search results will be listed on a new page and sorted by "UniProt_AC".
- You can select specific columns and sort them according to the information of searched proteins.
- You can export the search results list or customized selected list by multiple formats, such as .txt, .csv, .json, .xml et al ①.
- You can push the "Detail ②" button to access the detailed page of the specific WD40 protein.
| Display by default | Columns | Explanation |
|---|---|---|
| On | Accession Number | UniProt accession number (can be sorted) |
| On | Section | UniProt section, Swiss-Prot ir TrEMBL (can be sorted) |
| On | Entry Name | The UniProt entry name (can be sorted) |
| On | Protein Name | Full protein name (can be sorted) |
| On | Organism | The Latin and English name of organism (can be sorted) |
| On | WDSP Category | The assigned confidence category for that protein |
| On | Repeat Number | The predicted WD40 repeats number (can be sorted) |
| Off | WDSP Score | The average repeats score of prediction |
Protein Detail Page
Basic protein information
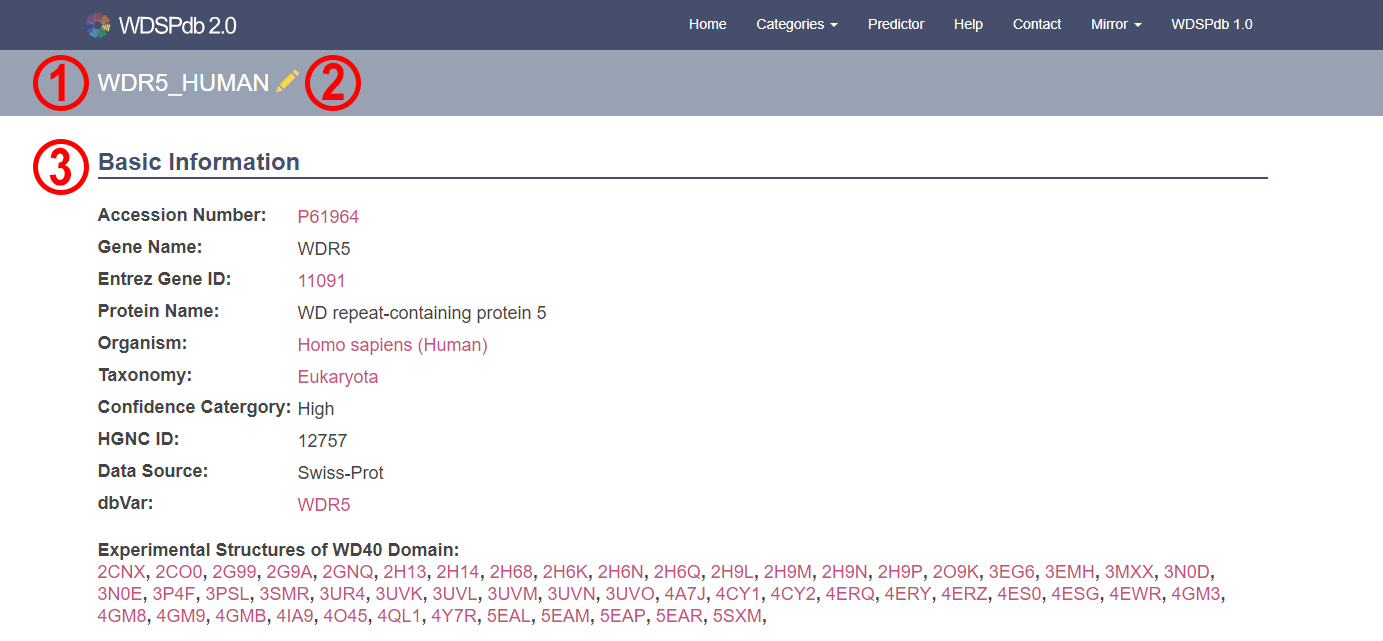
- Take WDR5_HUMAN ① information page as an example.
- The WD40 proteins which are manually reviewed and corrected the secondary structures according to the PDB structures are marked by yellow pencil ②.
- The basic information of the protein is displayed by a table at the top of the page ③.
- The information items about include:
| Items | Explanation |
|---|---|
| Accession Number | UniProt accession number |
| Gene Name | The gene symbol |
| Gene ID | Entrez gene ID |
| Protein Name | Full protein name |
| Organism | The Latin and English name of organism |
| Organism Domain | The highest taxonomic rank of organisms in the biological taxonomy |
| WDSP Category | The assigned confidence category for that protein |
| HGNC ID | The HGNC ID of the protein |
| Data Source | The protein is belong to the Swiss-Prot or TrEMBL |
| Experimental Structures of WD40 Domain | The experimental structures containing WD40 domain |
| Reference Sequence | protein ID or transcript ID in NCBI |
| Description | Alternative protein names |
| Functions | The annotated function in UniProt Knowledge Base |
| Ensembl ID | The Ensembl gene ID, transcript ID and protein ID |
The WD40 repeat and secondary structures
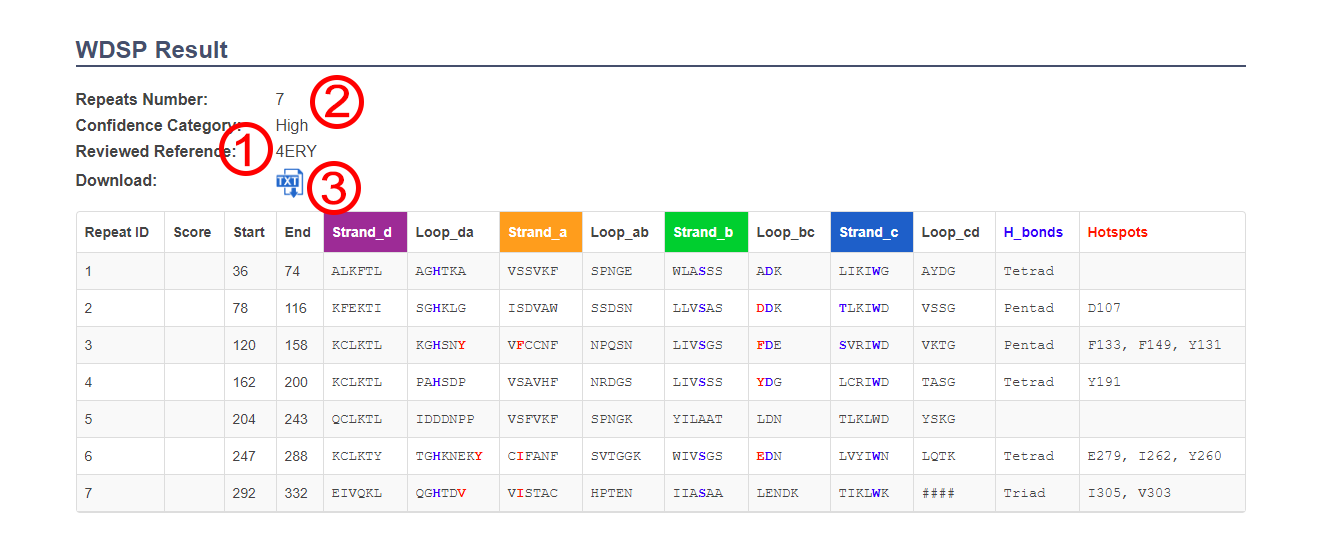
- In general, the WD40 repeats and secondary structures were predicted by updated WDSP. In special, they have been manually corrected according to the PDB structures when the “Reviewed reference” ① gave the PDB ID and “Average score” ② was empty.
- You can download the description of secondary structures as text format ③.
- Each line in the colored table is a single WD40 repeat. The columns described as follow table:
| Column | Explanation |
|---|---|
| Repeat ID | The WD40 repeat order number |
| Score | The WDSP predicted score of the WD40 repeat (mannually reviewed if empty) |
| Start | The start site of the WD40 repeat, means the first site of the strand_d |
| End | The first site of the loop_cd. The end site of last repeat is the followed site of the strand_c |
| Strand_d | The first strand of the WD40 repeat at the side face of the structure |
| Loop_da | The loop connecting the strand_d and strand_a at the top-side face of the structure |
| Strand_a | The second strand of the WD40 repeat at the inner face of the structure |
| Loop_ab | The loop connecting the strand_a and strand_b at the bottom face of the structure |
| Strand_b | The third strand of the WD40 repeat |
| Loop_bc | The loop connecting the strand_b and strand_c at the top face of the structure |
| Strand_c | The fourth strand of the WD40 repeat |
| Loop_cd | The loop connecting the strand_c and strand_d of next WD40 repeat at the side-bottom face of the structure |
| H_bonds | The residues participate in forming hydrogen bond networks of WD40 repeat (blue residues) |
| Hotspots | The potential hotspost residues on the top face (red residues) |
Structure model & Variants (if mapped)
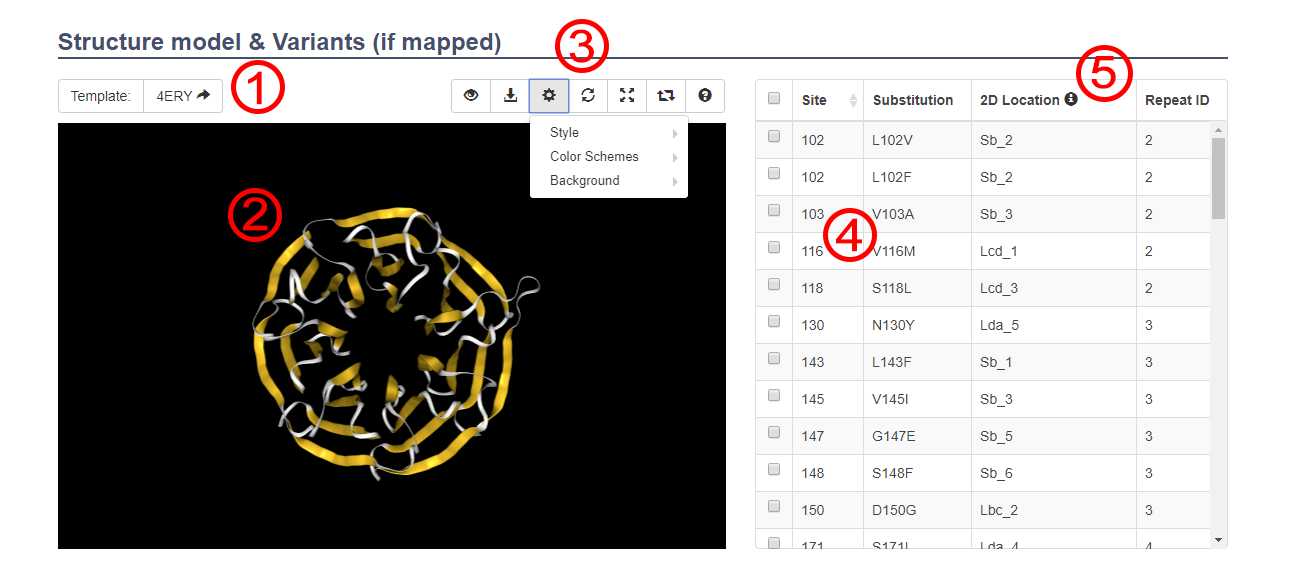
- All of the 3D structure models we displayed were modeled. And only the proteins which repeat number among 6, 7, 8 have models.
- When the template is the PDB ID, the structure used that experimental structures as template ①.
- When the template is the UniProt Accession Number, the structure used that protein model as the template.
- The secondary structures of 3D structure models have been annotated by predicted secondary structures. In the default color scheme, the yellow indicated the β-strand, the magenta indicated the α helix and the white indicated the loops ②.
- You can push the buttons on the action bar to view featured sites, download the 3D structure models or associated sequences, and change the structural display style ③.
- Additionally, you can check the specific variants in the checkbox table at the right side to display ④.
- The display color: sites of variants is grey; sites of hydrogen bond networks is blue; sites of variants on hydrogen bond networks is cyan; sites of potential hotspots is red; sites of variants on hotspots is pink;
- ⑤ The secondary structure locations of the variants in the WD40 repeats. For example: "Sa_6" means the sixth residue of strand a; "Lda_7" means the seventh residue of loop da.
| Button | Explanation |
|---|---|
| Template | Jump to the template page |
| View the featured sites include potential hotspots on the top face and hydrogen bond networks | |
| Download the 3D structure models or associated sequences | |
| Change the structural display style: style, color schemes or background | |
| Reset all actions | |
| Expand to full screen to view | |
| Let the structure spin | |
| Jump to the help of 3D structure viewer |
The variants table
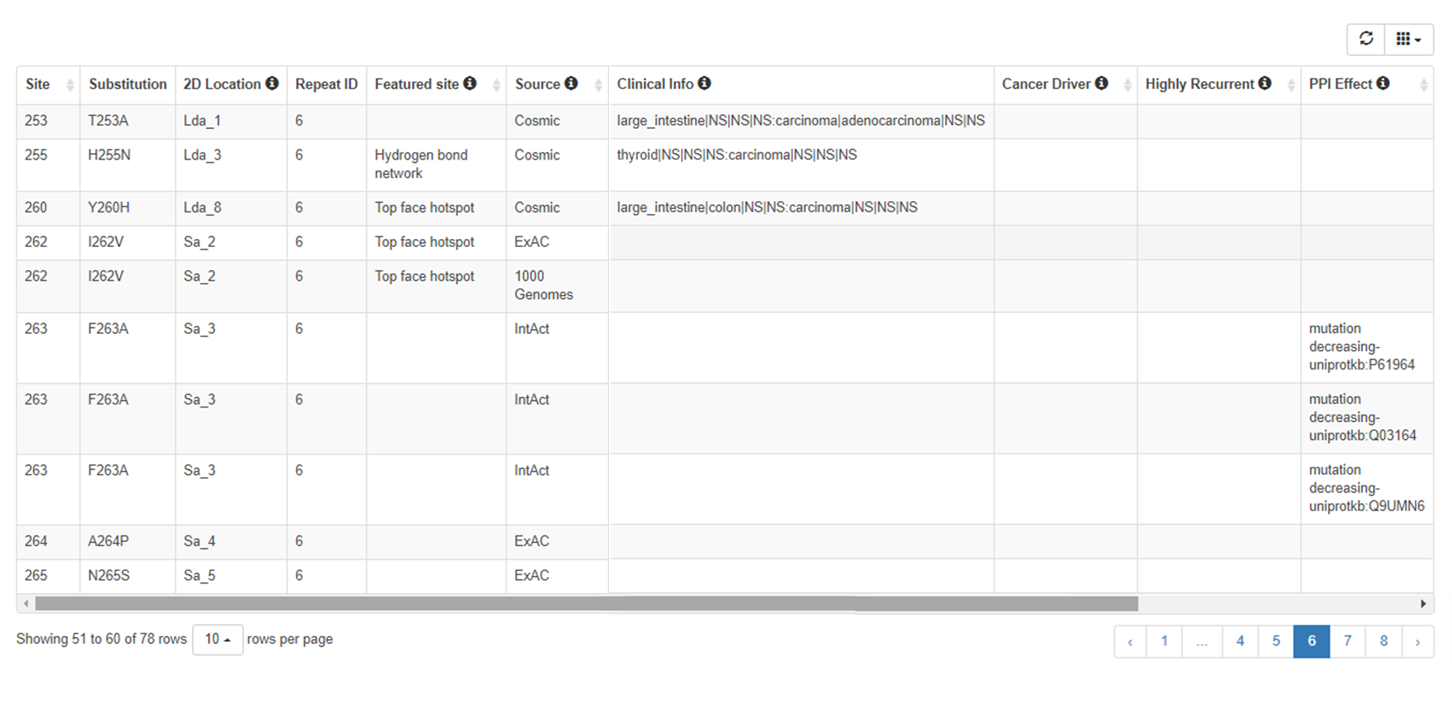
- The table showed the human missense variants of WD40 proteins which belong to “High” confidence category.
- These mutations/variants were collected from different datasets, include 1000 Genomes, Clinvar, ExAC, Cosmic.
- You can select and present specific columns about the mutations/variants information and sort them in the dynamic table.
| Display by default | Column | Explanation |
|---|---|---|
| On | Site | Variant site corresponding to the UniProt sequence |
| On | Substitution | The single amino acid substitution of the variant |
| On | 2D Location | The secondary structure location of the variant in that WD40 repeat |
| On | Repeat ID | The ordinal number of WD40 repeat where the variant are located |
| On | Featured site | The wild type residue of the variant is the member of the hydrogen bond network or hotspots on the top face |
| On | Resource | The data source or database of the variant |
| On | Clinical Info | The clinical information of the variant from ClinVar or Cosmic. Please see. |
| On | Cancer Driver | The associated cancer types driven by that variant, as annotated in IntOGen.Please see. |
| On | Highly Recurrent | Whether the variant is highly recurrent in cancer, as annotated in cBioPortal. Please see the answer of "Which resources are integrated for variant annotation?" at the FAQ page of cBioPortal. |
| On | PPI Effect | The variant effect on the interaction and specific partner, as annotated in the IntAct. Please see. |
| Off | Reference CDS Changes | The transcript codon changes of the variant |
| Off | Reference | The PMID of the reference which reported the variant |
| Off | Allele Frequency | The allele frequency of the variant from the dataset |
| Off | Chromosome Coordinate | The codon change site in the chromosome of the variant |
| Off | SIFT_score | Sorting Intolerant From Tolerant score, range from 0 to 1 |
| Off | SIFT_pred | Prediction of SIFT scores: "T(olerated)" or "D(amaging)", The score cutoff between "D" and "T" is 0.05. |
| Off | MutationAssessor_score | MutationAssessor functional impact combined score, The score ranges from -5.135 to 6.49 in dbNSFP. |
| Off | MutationAssessor_pred | MutationAssessor's functional impact of a variant : predicted functional, i.e. high ("H") or medium ("M"), or predicted non-functional, i.e. low ("L") or neutral ("N"). The MAori score cutoffs between "H" and "M", "M" and "L", and "L" and "N", are 3.5, 1.935 and 0.8, respectively. |
| Off | FATHMM_score | FATHMM default score (weighted for human inherited-disease mutations with Disease Ontology) (FATHMMori). Scores range from -16.13 to 10.64. The smaller the score the more likely the SNP has damaging effect. |
| Off | FATHMM_pred | If a FATHMM score is <=-1.5 (or rankscore >=0.81332) the corresponding nsSNV is predicted as "D(AMAGING)"; otherwise it is predicted as "T(OLERATED)". |
| Off | MetaSVM_score | Support vector machine (SVM) based ensemble prediction score, which incorporated 10 scores (SIFT, PolyPhen-2 HDIV, PolyPhen-2 HVAR, GERP++, MutationTaster, Mutation Assessor, FATHMM, LRT, SiPhy, PhyloP) and the maximum frequency observed in the 1000 genomes populations. Larger value means the SNV is more likely to be damaging. Scores range from -2 to 3 in dbNSFP. |
| Off | MetaSVM_pred | Prediction of our SVM based ensemble prediction score,"T(olerated)" or "D(amaging)". The score cutoff between "D" and "T" is 0. |
| Off | MetaLR_score | Logistic regression (LR) based ensemble prediction score, which incorporated 10 scores (SIFT, PolyPhen-2 HDIV, PolyPhen-2 HVAR, GERP++, MutationTaster, Mutation Assessor, FATHMM, LRT, SiPhy, PhyloP) and the maximum frequency observed in the 1000 genomes populations. Larger value means the SNV is more likely to be damaging. Scores range from 0 to 1. |
| Off | MetaLR_pred | Prediction of our MetaLR based ensemble prediction score,"T(olerated)" or "D(amaging)". The score cutoff between "D" and "T" is 0.5. |
| Off | CADD_phred | CADD score.The larger the score the more likely the SNP has damaging effect.If you would like to apply a cutoff on deleteriousness, e.g. to identify potentially pathogenic variants, we would suggest to put a cutoff somewhere between 10 and 20. Maybe at 15, as this also happens to be the median value for all possible canonical splice site changes and non-synonymous variants. However, there is not a natural choice here -- it is always arbitrary. We therefore recommend integrating C-scores with other evidence and to rank your candidates for follow up rather than hard filtering. |
| Off | ExAC_AC | Allele count in total ExAC samples (60,706 samples) |
| Off | ExAC_AF | Allele frequency in total ExAC samples |
| Off | ExAC_pLI | "The probability of being loss-of-function intolerant (intolerant of both heterozygous and homozygous lof variants)" based on ExAC r0.3 data |
| Off | ExAC_pRec | "The probability of being intolerant of homozygous, but not heterozygous lof variants" based on ExAC r0.3 data |
| Off | GDI | Gene damage index score, "a genome-wide, gene-level metric of the mutational damage that has accumulated in the general population" from doi: 10.1073/pnas.1518646112. The higher the score the less likely the gene is to be responsible for monogenic diseases. |
| Off | Essential_gene | Essential ("E") or Non-essential phenotype-changing ("N") based on Mouse Genome Informatics database. from doi:10.1371/journal.pgen.1003484 |
| Off | Polyphen2_HDIV_score | Polyphen2 score based on HumDiv. The score ranges from 0 to 1 |
| Off | Polyphen2_HDIV_pred | Polyphen2 prediction based on HumDiv, "D" ("probably damaging", HDIV score in [0.957,1]), "P" ("possibly damaging", HDIV score in [0.453,0.956]) and "B" ("benign", HDIV score in [0,0.452] ). Score cutoff for binary classification is 0.5 for HDIV score |
| Off | Polyphen2_HVAR_score | Polyphen2 score based on HumVar. The score ranges from 0 to 1. |
| Off | Polyphen2_HVAR_pred | Polyphen2 prediction based on HumVar, "D" ("probably damaging", HVAR score in [0.909,1]), "P" ("possibly damaging", HVAR in [0.447,0.908]) and "B" ("benign", HVAR score in [0,0.446]). Score cutoff for binary classification is 0.5 for HVAR score |
Clinical Information
ClinVar:Primary Tissue|Tissue Subtype1|Tissue Subtype2|Tissue Subtype3:Histology|Histology Subtype 1|Histology Subtype 2|Histology Subtype 3
| Primary Tissue | The primary tissue from which the sample originated. More details on the tissue classification can be found here |
| Tissue Subtype 1 | Further sub classifications of the samples tissue of origin |
| Tissue Subtype 2 | Further sub classifications of the samples tissue of origin. |
| Tissue Subtype 3 | Further sub classifications of the samples tissue of origin. |
| Histology | The histological classification of the sample |
| Histology Subtype 1 | Further histological classifications of the sample |
| Histology Subtype 2 | Further histological classifications of the sample |
| Histology Subtype 3 | Further histological classifications of the sample |
| NS | Not specify |
Cancer Driver
| Abbreviation | Full Name |
|---|---|
| ALL | acute lymphoid leukemia |
| AML | acute myeloid leukemia |
| BLCA | bladder carcinoma |
| BRCA | breast carcinoma |
| CLL | chronic lymphocytic leukemia |
| CM | cutaneous melanoma |
| COREAD | colorectal adenocarcinoma |
| DLBC | diffuse large B cell lymphoma |
| ESCA | esophageal carcinoma |
| GBM | glioblastoma multiforme |
| HC | hepatic carcinoma |
| HNSC | head and neck squamous cell carcinoma |
| LGG | lower grade glioma |
| LUAD | lung adenocarcinoma |
| LUSC | lung squamous cell carcinoma |
| MB | medulloblastoma |
| MM | multiple myeloma |
| NB | neuroblastoma |
| NSCLC | non small cell lung carcinoma |
| OV | serous ovarian adenocarcinoma |
| PA | pilocytic astrocytoma |
| PAAD | pancreas adenocarcinoma |
| PRAD | prostate adenocarcinoma |
| RCCC | renal clear cell carcinoma |
| SCLC | small cell lung carcinoma |
| STAD | stomach adenocarcinoma |
| THCA | thyroid carcinoma |
| UCEC | uterine corpus endometrioid carcinoma |
PPI Effect
- Mutation (MI:0118): A change in a sequence or structure in comparison to a reference entity due to a insertion, deletion or substitution event. This root term is used when there is a mutation present in a protein and the wild type version has not been tested or shown to interact in the referenced paper.
- Mutation causing an interaction (MI:2227): A change in a sequence or structure in comparison to a reference entity due to a insertion, deletion or substitution event that enables an interaction when compared with the wild-type, which does not interact.
- Mutation decreasing interaction (MI:0119): Region of a molecule whose mutation or deletion decreases significantly interaction strength or rate (in the case of interactions inferred from enzymatic reaction).
- Mutation decreasing interaction rate (MI:1130): Region of a molecule whose mutation or deletion decreases significantly interaction rate (in the case of interactions inferred from enzymatic reaction).
- Mutation decreasing interaction strength (MI:1133): Region of a molecule whose mutation or deletion decreases significantly interaction strength.
- Mutation disrupting interaction (MI:0573): Region of a molecule whose mutation or deletion totally disrupts an interaction strength or rate (in the case of interactions inferred from enzymatic reaction).
• Mutation disrupting interaction rate (MI:1129): Region of a molecule whose mutation or deletion totally disrupts an interaction rate (in the case of interactions inferred from enzymatic reaction).
• Mutation disrupting interaction strength (MI:1128): Region of a molecule whose mutation or deletion totally disrupts an interaction strength.
- Mutation increasing interaction (MI:0382): Region of a molecule whose mutation or deletion increases significantly interaction strength or rate (in the case of interactions inferred from enzymatic reaction).
- Mutation increasing interaction rate (MI:1131): Region of a molecule whose mutation or deletion increases significantly interaction rate (in the case of interactions inferred from enzymatic reaction).
- Mutation increasing interaction strength (MI:1132): Region of a molecule whose mutation or deletion increases significantly interaction strength.
- Mutation with no effect (MI:2226): A change in a sequence or structure in comparison to a reference entity due to a insertion, deletion or substitution event that does not have any effect over an interaction when compared with the wild-type.
Predictor Help
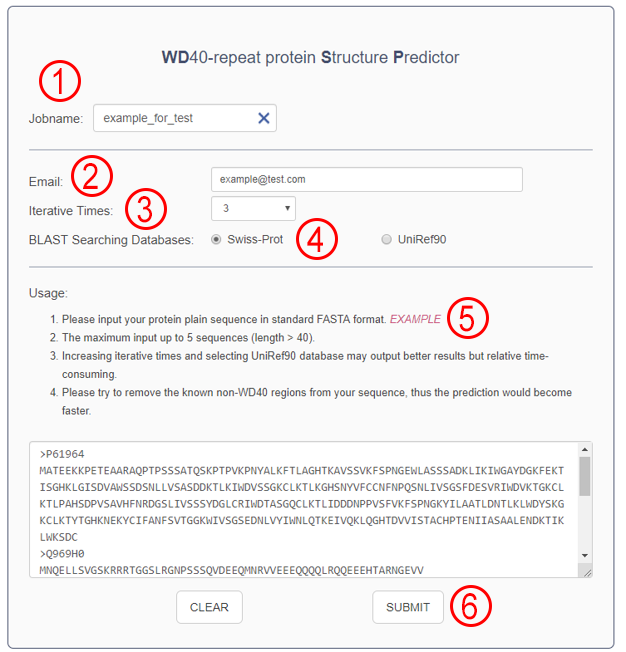
- You should input a jobname to name your submitted task. This is not allowed by empty ①.
- You should input your email address ② to get your prediction result link even you won’t leave the page. The resulting link will be saved for you for a month.
- You can select the iterative times ③ to get better results. The presented result just present the best one in all of your predictions.
- There are two BLAST searching databases ④: Swiss-Prot or UniRef90. You could choose the much larger database, UniRef90, to get better predictions. But you should notice chose the UniRef90 would be very time consuming.
- The input sequences must be standard FASTA format.
- The maximum input up to 5 sequences and any one length could not be less than 40. You can hit the “EXAMPLE” ⑤ to get the example input.
- Please try to cut the known non-WD40 regions from your sequence, thus the prediction would become faster.
- Push the “SUBMIT” button ⑥ to submit your task and it would jump to the result page when the task finished. In addition, your email would receive the result link at the same time.
Citations
If you use the data of WDSPdb or the WDSP predictor in you research, please cite the following papers:
- Ma, J., An, K., Zhou, J.B., Wu, N.S., Wang, Y., Ye, Z.Q., Wu, Y.D. (2019). WDSPdb: an updated resource for WD40 proteins. Bioinformatics, [PMID: 31161214]
- Wang, Y., Hu, X.J., Zou, X.D., Wu, X.H., Ye, Z.Q. and Wu, Y.D. (2015) WDSPdb: a database for WD40-repeat proteins. Nucleic Acids Res, 43 , D339-344. [PMID: 25348404]
- Wang, Y., Jiang, F., Zhuo, Z., Wu, X.H., Wu, Y.D. (2013). A Method for WD40 Repeat Detection and Secondary Structure Prediction. PLoS ONE , 8(6) , e65705. [PMID: 23776530]
- Wu, X.H., Wang, Y., Zhuo, Z.,Jiang, F., Wu, Y.D. (2012). Identifying the hotspots on the top faces of WD40-repeat proteins from their primary sequences by beta-bulges and DHSW tetrads. PLoS ONE , 7(8) , e43005. [PMID: 22916195]
Frequently Asked Questions
Question List:
Q. How do I search WDSPdb 2.0?
A. In the home page, WDSPdb 2.0 supply a search box. It includes two parts: an input box for the keyword used to searching and a dropdown menu for types the keyword belong to. There are 6 types of keywords (UniProt ID, UniProt AC, Gene Name, Entrez ID, Organism, Taxonomy). Besides them, the default of type is “All”, that means WDSPdb 2.0 will search your keyword in all 6 types, which will cost a long time.
Theoretically, you can use any string as keyword. But we have to remind you to input a keyword as short and accurate as possible in case you cannot get any result. Furthermore, please don’t use “AND” and “:” in your keyword, because they are reserved words of the web site. WDSPdb 2.0 would remove them from your keyword if you input them “carelessly”. Finally, if you input an empty string as keyword, WDSPdb 2.0 will return all entries (594,319 entries) no matter what type you select. Please don’t do this unless it is necessary.
To help you enter accurate keywords, the input box has candidate keywords prompt function. When you are entering, WDSPdb 2.0 will provides you with possible keywords based on the type you select. For example, if you select the “Organism” type and enter in “human”, WDSPdb 2.0 will provide you with 10 words as candidate keywords, such as “Homo sapiens (human)”. Please choose the candidate keywords as input as possible so that you can get more accurate results. It is important to note that WDSPdb 2.0 does not provide you with anything when you select “All” as type.
In addition, we also provide advanced search function. When you click “Add” on the right of “Search” button, below the origin search box a new search box will be added, which also contains the input box and dropdown menu. You can have up to 5 search boxes. Each search box represents a search condition, and they are related by “AND”. We will also provide “OR” and “NOT” later.
A. In the home page, WDSPdb 2.0 supply a search box. It includes two parts: an input box for the keyword used to searching and a dropdown menu for types the keyword belong to. There are 6 types of keywords (UniProt ID, UniProt AC, Gene Name, Entrez ID, Organism, Taxonomy). Besides them, the default of type is “All”, that means WDSPdb 2.0 will search your keyword in all 6 types, which will cost a long time.
Theoretically, you can use any string as keyword. But we have to remind you to input a keyword as short and accurate as possible in case you cannot get any result. Furthermore, please don’t use “AND” and “:” in your keyword, because they are reserved words of the web site. WDSPdb 2.0 would remove them from your keyword if you input them “carelessly”. Finally, if you input an empty string as keyword, WDSPdb 2.0 will return all entries (594,319 entries) no matter what type you select. Please don’t do this unless it is necessary.
To help you enter accurate keywords, the input box has candidate keywords prompt function. When you are entering, WDSPdb 2.0 will provides you with possible keywords based on the type you select. For example, if you select the “Organism” type and enter in “human”, WDSPdb 2.0 will provide you with 10 words as candidate keywords, such as “Homo sapiens (human)”. Please choose the candidate keywords as input as possible so that you can get more accurate results. It is important to note that WDSPdb 2.0 does not provide you with anything when you select “All” as type.
In addition, we also provide advanced search function. When you click “Add” on the right of “Search” button, below the origin search box a new search box will be added, which also contains the input box and dropdown menu. You can have up to 5 search boxes. Each search box represents a search condition, and they are related by “AND”. We will also provide “OR” and “NOT” later.
Q. How to export the list of search result?
A. After you set search conditions and click the “Search” button, WDSPdb 2.0 will display your search result as a table. There is a button like “” at the top right of the table, which can be clicked to export table content into various formats, such as .json, .xml, .csv, .txt, .sql and so on.
At the top left of the table, there is a dropdown menu, which contains two items: “Export Basic” and “Export Selected”. When you choose “Export Basic”, the export button will export the whole current page of this table. By default, each page of this table contains 25 entries. You can also change it to 10, 50, 100 or all entries of your search result by a dropdown menu at the bottom left of the table. In addition, each row of the table starts with a selection box. When you choose “Export Selected”, you can export several entries you selected.
A. After you set search conditions and click the “Search” button, WDSPdb 2.0 will display your search result as a table. There is a button like “” at the top right of the table, which can be clicked to export table content into various formats, such as .json, .xml, .csv, .txt, .sql and so on.
At the top left of the table, there is a dropdown menu, which contains two items: “Export Basic” and “Export Selected”. When you choose “Export Basic”, the export button will export the whole current page of this table. By default, each page of this table contains 25 entries. You can also change it to 10, 50, 100 or all entries of your search result by a dropdown menu at the bottom left of the table. In addition, each row of the table starts with a selection box. When you choose “Export Selected”, you can export several entries you selected.
Q. How to use the RESTful API to download the predict results?
A. WDSPdb 2.0 offered a REST API for downloading WDSP predicted result of each protein. The URL format of the API is as follows:
The protein you focus on must be included in WDSPdb 2.0. Therefore, we recommend that you export a list of proteins from the search results page before using this API. You can call the API programmatically to get results, but please note that we limit the API to only two requests per second for server performance reasons.
A. WDSPdb 2.0 offered a REST API for downloading WDSP predicted result of each protein. The URL format of the API is as follows:
www.wdspdb.com/wdsp/detail/{UniProt AC}.txt
You can replace {UniProt AC} with a specific Accession Number of a protein in UniProt database. And WDSPdb 2.0 will return the WDSP predicted result of this protein. For example, if you want to get the predicted result of WDR5_HUMAN whose Accession Number is "P61964", then your URL is www.wdspdb.com/wdsp/detail/P61964.txt. Don’t forget “.txt” at the end.The protein you focus on must be included in WDSPdb 2.0. Therefore, we recommend that you export a list of proteins from the search results page before using this API. You can call the API programmatically to get results, but please note that we limit the API to only two requests per second for server performance reasons.
Q. Why doesn't my browser display the web site correctly?
A. WDSPdb 2.0 is compatible to most modern web browsers, like Chrome, Firefox, Microsoft Edge, and Safari. If your browser does not display the site correctly, please check weather all components have been loaded because sometimes the network has problem. Please do not browse the website in IE browser, because the plug-in we use is not compatible with it. In addition, if you find any bug, please click "Contact" on the top to tell us.
A. WDSPdb 2.0 is compatible to most modern web browsers, like Chrome, Firefox, Microsoft Edge, and Safari. If your browser does not display the site correctly, please check weather all components have been loaded because sometimes the network has problem. Please do not browse the website in IE browser, because the plug-in we use is not compatible with it. In addition, if you find any bug, please click "Contact" on the top to tell us.